HTML总结
- Authors

- 作者
- 孙一凡
前言
对于前端开发者来说,不管是对初学者还是已独当一面的资深前端开发者,HTML 都是最基础的内容。
今天,主要介绍 HTML 和网页有什么关系,以及与 DOM 有什么不同。通过本讲内容,你将掌握浏览器是怎么处理 HTML 内容的,以及在这个过程中我们可以进行怎样的处理来提升网页的性能,从而提升用户的体验。
浏览器页面加载过程
不知你是否有过这样的体验:当打开某个浏览器的时候,发现一直在转圈,或者等了好长时间才打开页面……
此时的你,会选择关掉页面还是耐心等待呢?
这一现象,除了网络不稳定、网速过慢等原因,大多数都是由于页面设计不合理导致加载时间过长导致的。
我们都知道,页面是用 HTML/CSS/JavaScript 来编写的。
其中,HTML 的职责在于告知浏览器如何组织页面,以及搭建页面的基本结构; CSS 用来装饰 HTML,让我们的页面更好看; JavaScript 则可以丰富页面功能,使静态页面动起来。
HTML 由一系列的元素组成,通常称为 HTML 元素。HTML 元素通常被用来定义一个网页结构,基本上所有网页都是这样的 HTML 结构:
<html>
<head></head>
<body></body>
</html>
其中:
<html>元素是页面的根元素,它描述完整的网页;<head>元素包含了我们想包含在 HTML 页面中,但不希望显示在网页里的内容;<body>元素包含了我们访问页面时所有显示在页面上的内容,是用户最终能看到的内容。
HTML 中的元素特别多,其中还包括可用于 Web Components 的自定义元素。
前面我们提到页面 HTML 结构不合理可能会导致页面响应慢,这个过程很多时候体现在<script>和<style>元素的设计上,它们会影响页面加载过程中对 Javascript 和 CSS 代码的处理。
因此,如果想要提升页面的加载速度,就需要了解浏览器页面的加载过程是怎样的,从根本上来解决问题。
浏览器在加载页面的时候会用到 GUI 渲染线程和 JavaScript 引擎线程。其中,GUI 渲染线程负责渲染浏览器界面 HTML 元素,JavaScript 引擎线程主要负责处理 JavaScript 脚本程序。
由于 JavaScript 在执行过程中还可能会改动界面结构和样式,因此它们之间被设计为互斥的关系。也就是说,当 JavaScript 引擎执行时,GUI 线程会被挂起。
以京东官网为例,我们来看看网页加载流程。
(1)当我们打开京东官网的时候,浏览器会从服务器中获取到 HTML 内容。
(2)浏览器获取到 HTML 内容后,就开始从上到下解析 HTML 的元素。
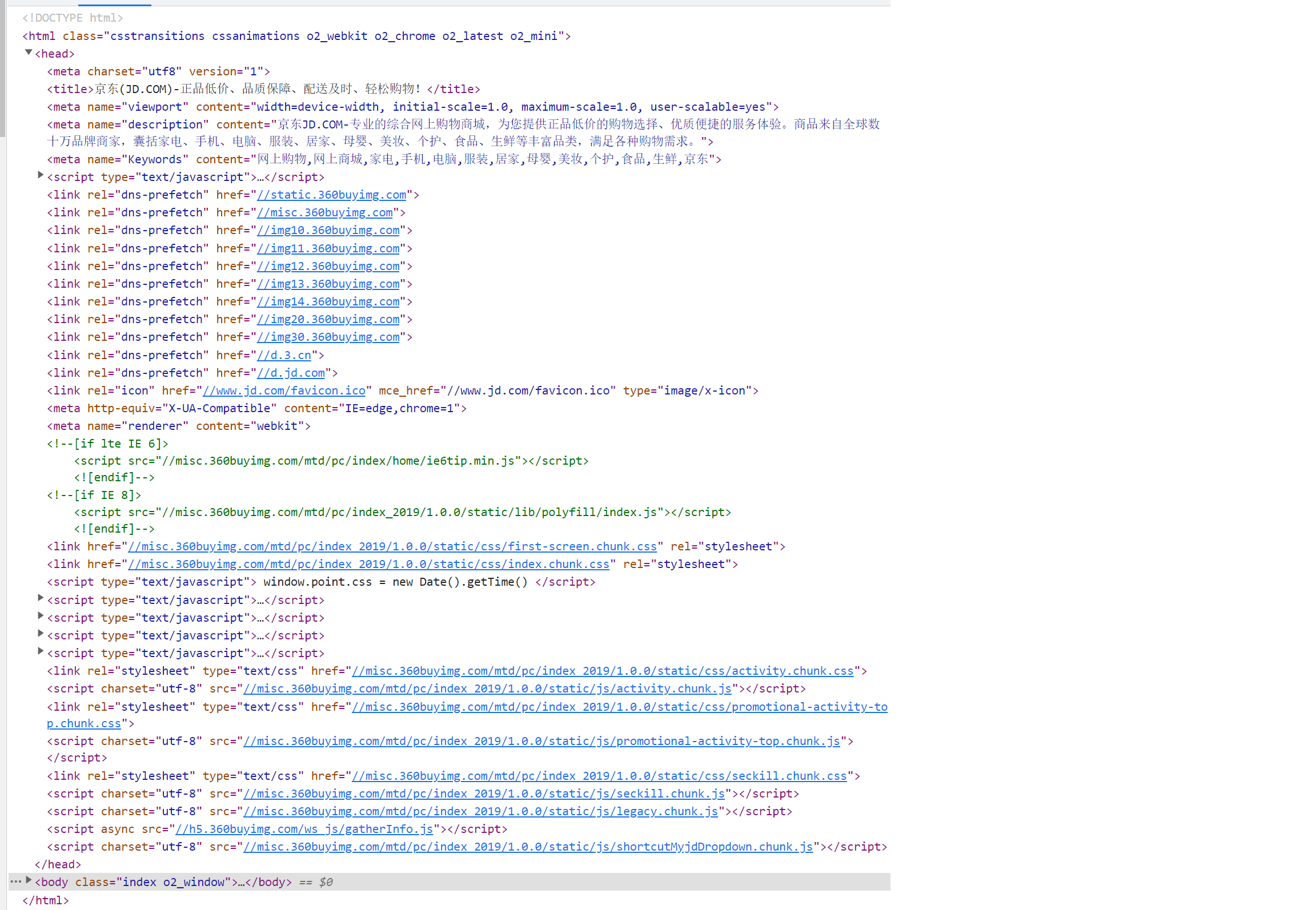
(3)<head>元素内容会先被解析,此时浏览器还没开始渲染页面。
我们看到
<head>元素里有用于描述页面元数据的<meta>元素,还有一些<link>元素涉及外部资源(如图片、CSS 样式等),此时浏览器会去获取这些外部资源。 除此之外,我们还能看到<head>元素中还包含着不少的<script>元素,这些<script>元素通过src属性指向外部资源。
(4)当浏览器解析到这里时(步骤 3),会暂停解析并下载 JavaScript 脚本。
(5)当 JavaScript 脚本下载完成后,浏览器的控制权转交给 JavaScript 引擎。当脚本执行完成后,控制权会交回给渲染引擎,渲染引擎继续往下解析 HTML 页面。
(6)此时<body>元素内容开始被解析,浏览器开始渲染页面。
在这个过程中,我们看到<head>中放置的<script>元素会阻塞页面的渲染过程:把 JavaScript 放在<head>里,意味着必须把所有 JavaScript 代码都下载、解析和解释完成后,才能开始渲染页面。
到这里,我们就明白了:如果外部脚本加载时间很长(比如一直无法完成下载),就会造成网页长时间失去响应,浏览器就会呈现“假死”状态,用户体验会变得很糟糕。
因此,对于对性能要求较高、需要快速将内容呈现给用户的网页,常常会将 JavaScript 脚本放在<body>的最后面。这样可以避免资源阻塞,页面得以迅速展示。我们还可以使用defer/async/preload等属性来标记<script>标签,来控制 JavaScript 的加载顺序。
我们再来看看百度首页。
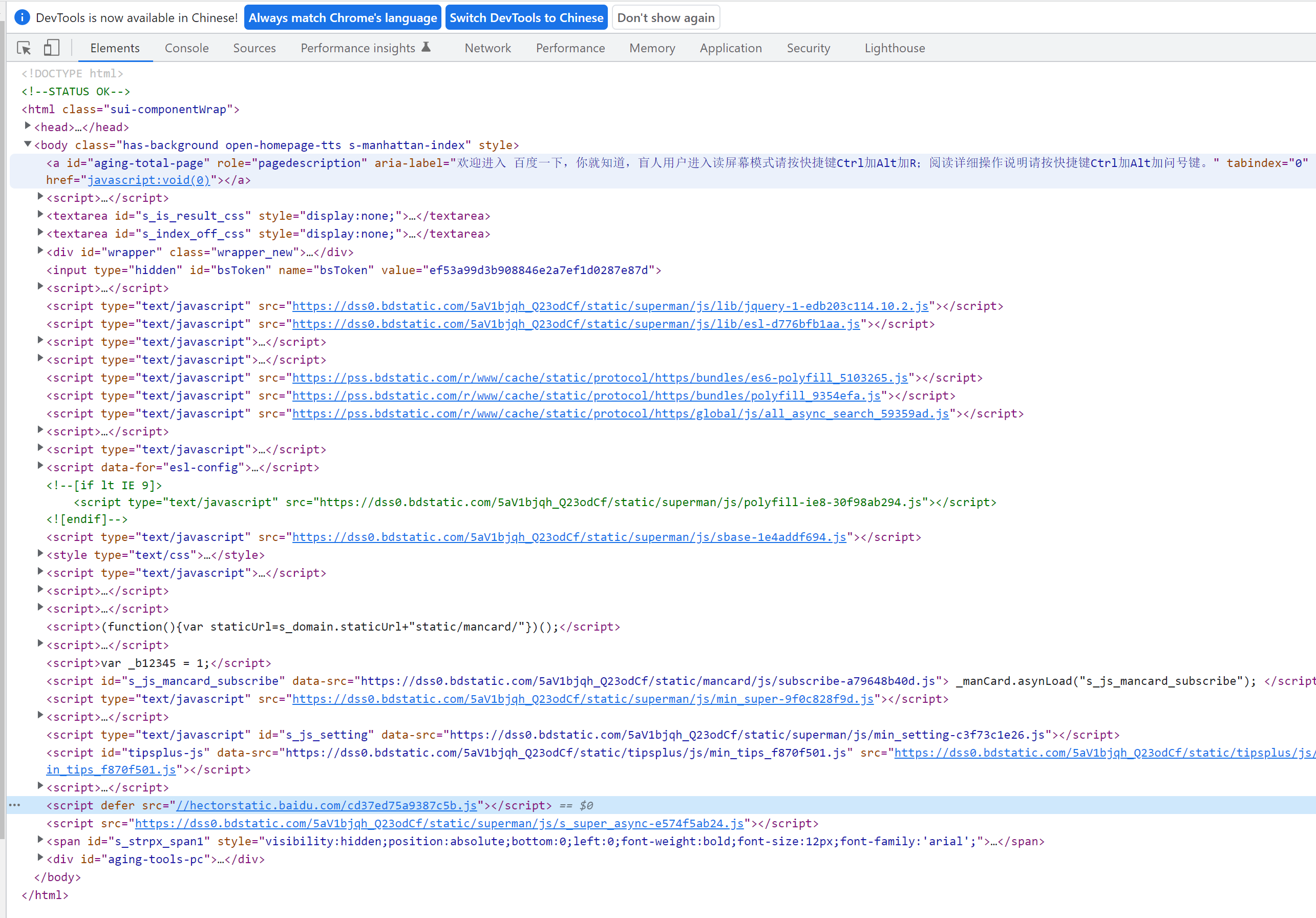
可以看到,虽然百度首页的<head>元素里也包括了一些<script>元素,但大多数都加上了async属性。async属性会让这些脚本并行进行请求获取资源,同时当资源获取完成后尽快解析和执行,这个过程是异步的,不会阻塞 HTML 的解析和渲染。
对于百度这样的搜索引擎来说,必须要在最短的时间内提供到可用的服务给用户,其中就包括搜索框的显示及可交互,除此之外的内容优先级会相对较低。
浏览器在渲染页面的过程需要解析 HTML、CSS 以得到 DOM 树和 CSS 规则树,它们结合后才生成最终的渲染树并渲染。因此,我们还常常将 CSS 放在<head>里,可用来避免浏览器渲染的重复计算。
###HTML 与 DOM 有什么不同
我们知道<p>是 HTML 元素,但又常常将<p>这样一个元素称为 DOM 节点,那么 HTML 和 DOM 到底有什么不一样呢?
根据 MDN 官方描述:文档对象模型(DOM)是 HTML 和 XML 文档的编程接口。
也就是说,DOM 是用来操作和描述 HTML 文档的接口。如果说浏览器用 HTML 来描述网页的结构并渲染,那么使用 DOM 则可以获取网页的结构并进行操作。一般来说,我们使用 JavaScript 来操作 DOM 接口,从而实现页面的动态变化,以及用户的交互操作。
在开发过程中,常常用对象的方式来描述某一类事物,用特定的结构集合来描述某些事物的集合。DOM 也一样,它将 HTML 文档解析成一个由 DOM 节点以及包含属性和方法的相关对象组成的结构集合。
比如这里,我们在京东官网中检查滚动控制面板的元素,如下图所示:
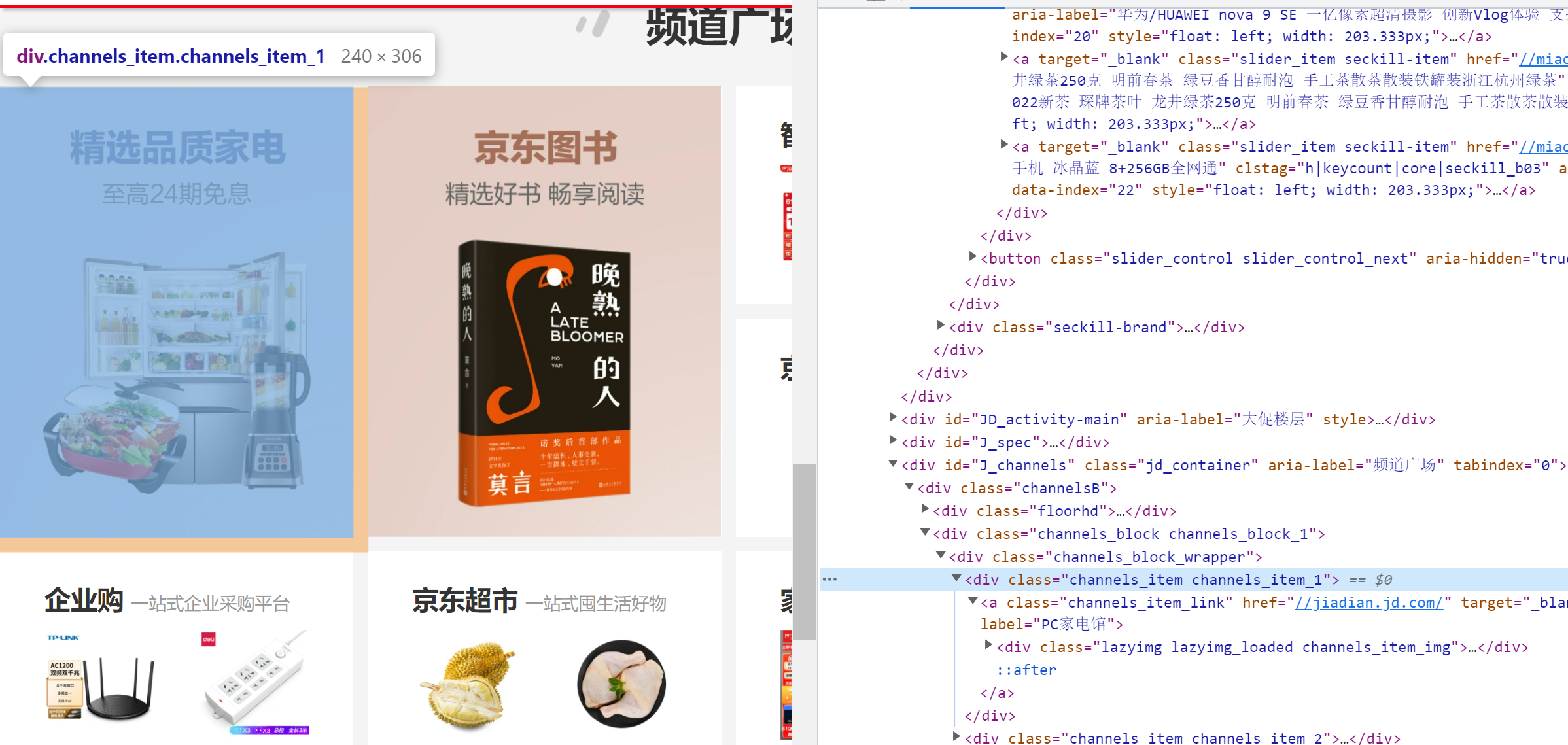
可以在控制台中获取到该滚动控制面板对应的 DOM 节点,通过右键保存到临时变量后,便可以在 console 面板中通过 DOM 接口获取该节点的信息,或者进行一些修改节点的操作,如下图所示:
我们来看看,浏览器中的 HTML 是怎样被解析成 DOM 的。
####DOM 解析
我们常见的 HTML 元素,在浏览器中会被解析成节点。比如下面这样的 HTML 内容:
<html>
<head>
<title>文档标题</title>
</head>
<body>
<a href="xxx.com">我的链接</a>
<h1>我的标题</h1>
</body>
</html>
打开控制台 Elements 面板,可以看到这样的 HTML 结构,如下图所示:
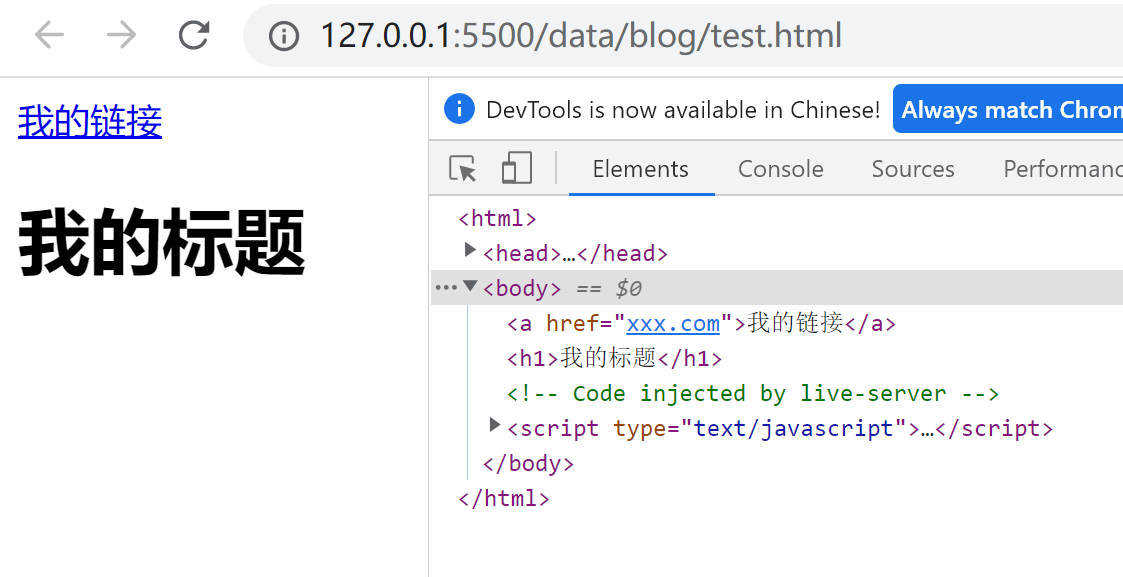
在浏览器中,上面的 HTML 会被解析成这样的 DOM 树,如下图所示:
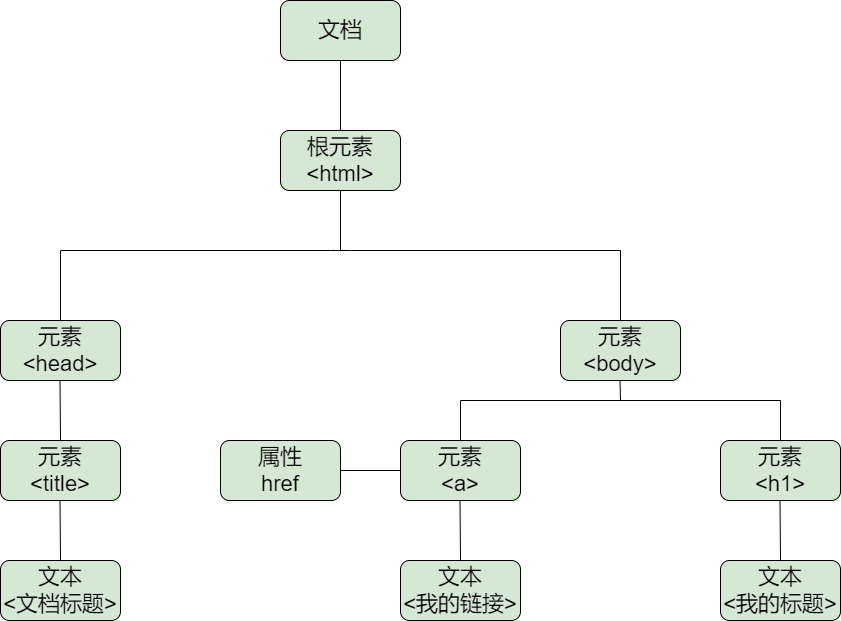
我们都知道,对于树状结构来说,常常使用parent/child/sibling等方式来描述各个节点之间的关系,对于 DOM 树也不例外。或许对于很多前端开发者来说,“DOM 是树状结构”已经是个过于基础的认识,因此我们也常常忽略掉开发过程中对它的依赖程度。
举个例子,我们常常会对页面功能进行抽象,并封装成组件。但不管怎么进行整理,页面最终依然是基于 DOM 的树状结构,因此组件也是呈树状结构,组件间的关系也同样可以使用parent/child/sibling这样的方式来描述。
同时,现在大多数应用程序同样以root为根节点展开,我们进行状态管理、数据管理也常常会呈现出树状结构,这在 Angular.js 升级到 Angular 的过程中也有所体现。Angular 增加了树状结构的模块化设计,不管是脏检查机制,还是依赖注入的管理,都由于这样的调整提升了性能、降低了模块间的耦合程度。
操作 DOM
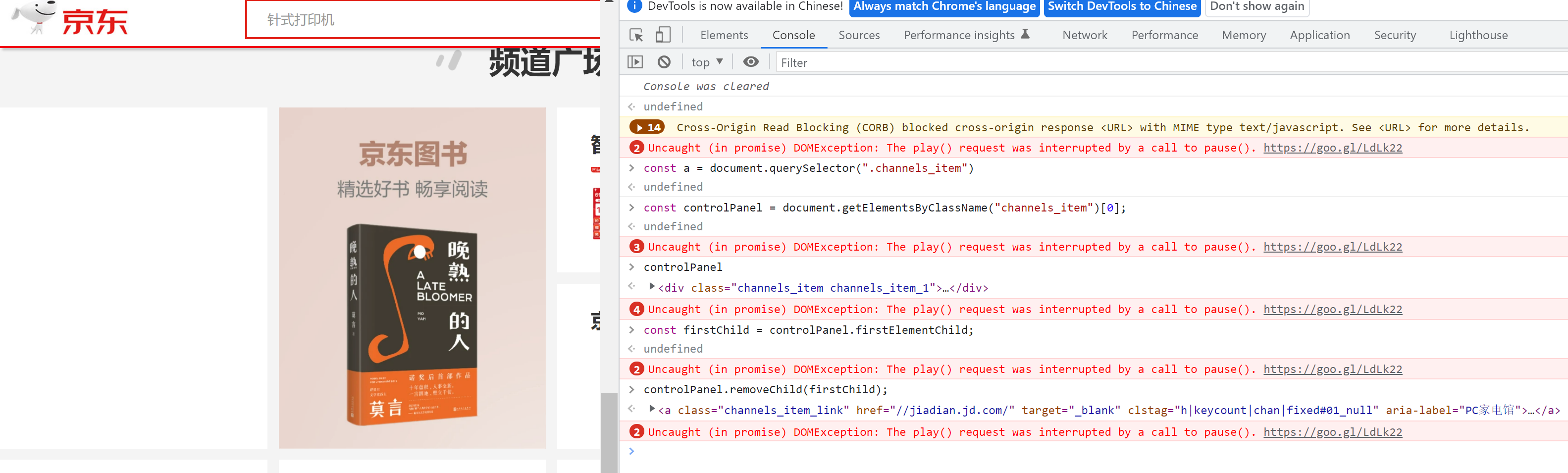
除了获取 DOM 结构以外,通过 HTMLDOM 相关接口,我们还可以使用 JavaScript 来访问 DOM 树中的节点,也可以创建或删除节点。比如我们想在上面的频道广场元素中删除一个频道子列,可以这么操作:
// 获取到 class 为 channels_item 的第一个节点,这里得到我们的频道广场元素
const controlPanel = document.getElementsByClassName('channels_item')[0]
// 获取频道广场元素的第一个子节点
const firstChild = controlPanel.firstElementChild
// 删除频道广场元素的子节点
controlPanel.removeChild(firstChild)
操作之后,我们能看到节点被顺利删除,如下图所示:
随着应用程序越来越复杂,DOM 操作越来越频繁,需要监听事件和在事件回调更新页面的 DOM 操作也越来越多,频繁的 DOM 操作会导致页面频繁地进行计算和渲染,导致不小的性能开销。于是虚拟 DOM 的想法便被人提出,并在许多框架中都有实现。
虚拟 DOM 其实是用来模拟真实 DOM 的中间产物,它的设计大致可分成 3 个过程:
用 JavaScript 对象模拟 DOM 树,得到一棵虚拟 DOM 树;
当页面数据变更时,生成新的虚拟 DOM 树,比较新旧两棵虚拟 DOM 树的差异;
把差异应用到真正的 DOM 树上。
后面我在介绍前端框架时,会更详细地介绍虚拟 DOM 部分的内容。
事件委托
我们知道,浏览器中各个元素从页面中接收事件的顺序包括事件捕获阶段、目标阶段、事件冒泡阶段。其中,基于事件冒泡机制,我们可以实现将子元素的事件委托给父级元素来进行处理,这便是事件委托。
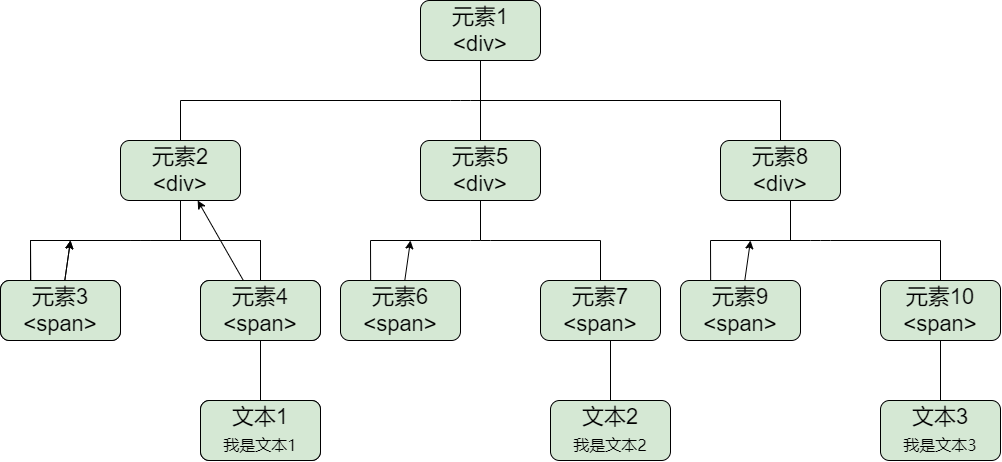
如果我们在每个元素上都进行监听的话,则需要绑定三个事件。
function clickEventFunction(e) {
console.log(e.target === this) // logs `true`
// 这里可以用 this 获取当前元素
// 此处控制元素的展示内容
}
// 元素2、5、8绑定
element2.addEventListener('click', clickEventFunction, false)
element5.addEventListener('click', clickEventFunction, false)
element8.addEventListener('click', clickEventFunction, false)
使用事件委托,可以通过将事件添加到它们的父节点,而将事件委托给父节点来触发处理函数:
function clickEventFunction(event) {
console.log(e.target === this) // logs `false`
// 获取被点击的元素
const eventTarget = event.target
// 检查源元素`event.target`是否符合预期
// 此处控制元素的展示内容
}
// 元素1绑定
element1.addEventListener('click', clickEventFunction, false)
这样能解决什么问题呢?
绑定子元素会绑定很多次的事件,而绑定父元素只需要一次绑定。
将事件委托给父节点,这样我们对子元素的增加和删除、移动等,都不需要重新进行事件绑定。
常见的使用方式主要是上述这种列表结构,每个选项都可以进行编辑、删除、添加标签等功能,而把事件委托给父元素,不管我们新增、删除、更新选项,都不需要手动去绑定和移除事件。
如果在列表数量内容较大的时候,对成千上万节点进行事件监听,也是不小的性能消耗。使用事件委托的方式,我们可以大量减少浏览器对元素的监听,也是在前端性能优化中比较简单和基础的一个做法。
需要注意的是,如果我们直接在document.body上进行事件委托,可能会带来额外的问题。由于浏览器在进行页面渲染的时候会有合成的步骤,合成的过程会先将页面分成不同的合成层,而用户与浏览器进行交互的时候需要接收事件。此时,浏览器会将页面上具有事件处理程序的区域进行标记,被标记的区域会与主线程进行通信。
如果我们document.body上被绑定了事件,这时候整个页面都会被标记。即使我们的页面不关心某些部分的用户交互,合成器线程也必须与主线程进行通信,并在每次事件发生时进行等待。这种情况,我们可以使用passive: true选项来解决。
小结
关于 HTML,主要讲了 HTML 的作用,以及它是如何影响浏览器中页面的加载过程的,同时还介绍了使用 DOM 接口来控制 HTML 的展示和功能逻辑。
很多时候,我们对一些基础内容也都需要不定期地进行复习。古人云“温故而知新”,一些原本认为已经固化的认知,在重新学习的过程中,或许你可以得到新的理解。比如,虚拟 DOM 的设计其实参考了网页中 DOM 设计的很多地方(树状结构、DOM 属性),却又通过简化、新旧对比的方式巧妙地避开了容易出现性能瓶颈的地方,从而提升了页面渲染的性能。
再比如,很多前端框架在监测数据变更的时候采用了树状结构(Angular 2.0+、Vue 3.0+),也是因为即使我们对应用进行了模块化、组件化,最终它在浏览器页面中的呈现和组织方式也依然是树状的,而树状的方式也很好地避免了循环依赖的问题。